Coverage Error¶
Module Interface¶
- class torchmetrics.classification.MultilabelCoverageError(num_labels, ignore_index=None, validate_args=True, **kwargs)[source]¶
Compute Multilabel coverage error.
The score measure how far we need to go through the ranked scores to cover all true labels. The best value is equal to the average number of labels in the target tensor per sample.
As input to
forwardandupdatethe metric accepts the following input:preds(Tensor): A float tensor of shape(N, C, ...). Preds should be a tensor containing probabilities or logits for each observation. If preds has values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element.target(Tensor): An int tensor of shape(N, C, ...). Target should be a tensor containing ground truth labels, and therefore only contain {0,1} values (except if ignore_index is specified).
Note
Additional dimension
...will be flattened into the batch dimension.As output to
forwardandcomputethe metric returns the following output:mlce(Tensor): A tensor containing the multilabel coverage error.
- Parameters:
Example
>>> from torchmetrics.classification import MultilabelCoverageError >>> _ = torch.manual_seed(42) >>> preds = torch.rand(10, 5) >>> target = torch.randint(2, (10, 5)) >>> mlce = MultilabelCoverageError(num_labels=5) >>> mlce(preds, target) tensor(3.9000)
- plot(val=None, ax=None)[source]¶
Plot a single or multiple values from the metric.
- Parameters:
val¶ (
Union[Tensor,Sequence[Tensor],None]) – Either a single result from calling metric.forward or metric.compute or a list of these results. If no value is provided, will automatically call metric.compute and plot that result.ax¶ (
Optional[Axes]) – An matplotlib axis object. If provided will add plot to that axis
- Return type:
- Returns:
Figure object and Axes object
- Raises:
ModuleNotFoundError – If matplotlib is not installed
>>> from torch import rand, randint >>> # Example plotting a single value >>> from torchmetrics.classification import MultilabelCoverageError >>> metric = MultilabelCoverageError(num_labels=3) >>> metric.update(rand(20, 3), randint(2, (20, 3))) >>> fig_, ax_ = metric.plot()
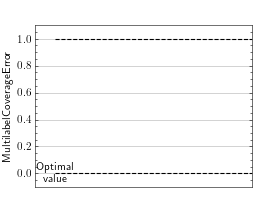
>>> from torch import rand, randint >>> # Example plotting multiple values >>> from torchmetrics.classification import MultilabelCoverageError >>> metric = MultilabelCoverageError(num_labels=3) >>> values = [ ] >>> for _ in range(10): ... values.append(metric(rand(20, 3), randint(2, (20, 3)))) >>> fig_, ax_ = metric.plot(values)
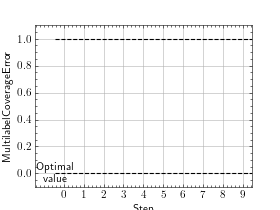
Functional Interface¶
- torchmetrics.functional.classification.multilabel_coverage_error(preds, target, num_labels, ignore_index=None, validate_args=True)[source]¶
Compute multilabel coverage error [1].
The score measure how far we need to go through the ranked scores to cover all true labels. The best value is equal to the average number of labels in the target tensor per sample.
Accepts the following input tensors:
preds(float tensor):(N, C, ...). Preds should be a tensor containing probabilities or logits for each observation. If preds has values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element.target(int tensor):(N, C, ...). Target should be a tensor containing ground truth labels, and therefore only contain {0,1} values (except if ignore_index is specified).
Additional dimension
...will be flattened into the batch dimension.- Parameters:
- Return type:
Example
>>> from torchmetrics.functional.classification import multilabel_coverage_error >>> _ = torch.manual_seed(42) >>> preds = torch.rand(10, 5) >>> target = torch.randint(2, (10, 5)) >>> multilabel_coverage_error(preds, target, num_labels=5) tensor(3.9000)
References
[1] Tsoumakas, G., Katakis, I., & Vlahavas, I. (2010). Mining multi-label data. In Data mining and knowledge discovery handbook (pp. 667-685). Springer US.
