Word Error Rate¶
Module Interface¶
- class torchmetrics.WordErrorRate(**kwargs)[source]
Word error rate (WordErrorRate) is a common metric of the performance of an automatic speech recognition system. This value indicates the percentage of words that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a WER of 0 being a perfect score. Word error rate can then be computed as:
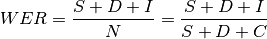
- where:
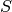 is the number of substitutions,
is the number of substitutions,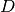 is the number of deletions,
is the number of deletions,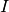 is the number of insertions,
is the number of insertions,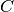 is the number of correct words,
is the number of correct words,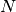 is the number of words in the reference (
is the number of words in the reference (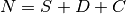 ).
).
Compute WER score of transcribed segments against references.
- Parameters
kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.- Returns
Word error rate score
Examples
>>> preds = ["this is the prediction", "there is an other sample"] >>> target = ["this is the reference", "there is another one"] >>> metric = WordErrorRate() >>> metric(preds, target) tensor(0.5000)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- update(preds, target)[source]
Store references/predictions for computing Word Error Rate scores.
Functional Interface¶
- torchmetrics.functional.word_error_rate(preds, target)[source]
Word error rate (WordErrorRate) is a common metric of the performance of an automatic speech recognition system. This value indicates the percentage of words that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a WER of 0 being a perfect score.
- Parameters
- Return type
- Returns
Word error rate score
Examples
>>> preds = ["this is the prediction", "there is an other sample"] >>> target = ["this is the reference", "there is another one"] >>> word_error_rate(preds=preds, target=target) tensor(0.5000)
