Jaccard Index¶
Module Interface¶
CohenKappa¶
- class torchmetrics.JaccardIndex(num_classes, average='macro', ignore_index=None, absent_score=0.0, threshold=0.5, multilabel=False, **kwargs)[source]
Note
From v0.10 an ‘binary_*’, ‘multiclass_*’, `’multilabel_*’ version now exist of each classification metric. Moving forward we recommend using these versions. This base metric will still work as it did prior to v0.10 until v0.11. From v0.11 the task argument introduced in this metric will be required and the general order of arguments may change, such that this metric will just function as an single entrypoint to calling the three specialized versions.
Computes Intersection over union, or Jaccard index:
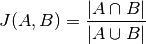
Where:
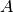 and
and 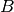 are both tensors of the same size, containing integer class values.
They may be subject to conversion from input data (see description below). Note that it is different from box IoU.
are both tensors of the same size, containing integer class values.
They may be subject to conversion from input data (see description below). Note that it is different from box IoU.Works with binary, multiclass and multi-label data. Accepts probabilities from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument to convert into integer labels. This is the case for binary and multi-label probabilities.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
average¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied. Should be one of the following:
'macro'[default]: Calculate the metric for each class separately, and average the metrics across classes (with equal weights for each class).'micro': Calculate the metric globally, across all samples and classes.'weighted': Calculate the metric for each class separately, and average the metrics across classes, weighting each class by its support (tp + fn).'none'orNone: Calculate the metric for each class separately, and return the metric for every class. Note that if a given class doesn’t occur in the preds or target, the value for the class will benan.
ignore_index¶ (
Optional[int]) – optional int specifying a target class to ignore. If given, this class index does not contribute to the returned score, regardless of reduction method. Has no effect if given an int that is not in the range [0, num_classes-1]. By default, no index is ignored, and all classes are used.absent_score¶ (
float) – score to use for an individual class, if no instances of the class index were present inpredsAND no instances of the class index were present intarget. For example, if we have 3 classes, [0, 0] forpreds, and [0, 2] fortarget, then class 1 would be assigned the absent_score.threshold¶ (
float) – Threshold value for binary or multi-label probabilities.multilabel¶ (
bool) – determines if data is multilabel or not.kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
Example
>>> from torchmetrics import JaccardIndex >>> target = torch.randint(0, 2, (10, 25, 25)) >>> pred = torch.tensor(target) >>> pred[2:5, 7:13, 9:15] = 1 - pred[2:5, 7:13, 9:15] >>> jaccard = JaccardIndex(num_classes=2) >>> jaccard(pred, target) tensor(0.9660)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
BinaryJaccardIndex¶
- class torchmetrics.classification.BinaryJaccardIndex(threshold=0.5, ignore_index=None, validate_args=True, **kwargs)[source]
Calculates the Jaccard index for binary tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds(int or float tensor):(N, ...). If preds is a floating point tensor with values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element. Addtionally, we convert to int tensor with thresholding using the value inthreshold.target(int tensor):(N, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
threshold¶ (
float) – Threshold for transforming probability to binary (0,1) predictionsignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationnormalize¶ –
Normalization mode for confusion matrix. Choose from:
Noneor'none': no normalization (default)'true': normalization over the targets (most commonly used)'pred': normalization over the predictions'all': normalization over the whole matrix
validate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
- Example (preds is int tensor):
>>> from torchmetrics.classification import BinaryJaccardIndex >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0, 1, 0, 0]) >>> metric = BinaryJaccardIndex() >>> metric(preds, target) tensor(0.5000)
- Example (preds is float tensor):
>>> from torchmetrics.classification import BinaryJaccardIndex >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0.35, 0.85, 0.48, 0.01]) >>> metric = BinaryJaccardIndex() >>> metric(preds, target) tensor(0.5000)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
MulticlassJaccardIndex¶
- class torchmetrics.classification.MulticlassJaccardIndex(num_classes, average='macro', ignore_index=None, validate_args=True, **kwargs)[source]
Calculates the Jaccard index for multiclass tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds:(N, ...)(int tensor) or(N, C, ..)(float tensor). If preds is a floating point we applytorch.argmaxalong theCdimension to automatically convert probabilities/logits into an int tensor.target(int tensor):(N, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
num_classes¶ (
int) – Integer specifing the number of classesignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationaverage¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied over labels. Should be one of the following:
micro: Sum statistics over all labelsmacro: Calculate statistics for each label and average themweighted: Calculates statistics for each label and computes weighted average using their support"none"orNone: Calculates statistic for each label and applies no reduction
validate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
- Example (pred is integer tensor):
>>> from torchmetrics.classification import MulticlassJaccardIndex >>> target = torch.tensor([2, 1, 0, 0]) >>> preds = torch.tensor([2, 1, 0, 1]) >>> metric = MulticlassJaccardIndex(num_classes=3) >>> metric(preds, target) tensor(0.6667)
- Example (pred is float tensor):
>>> from torchmetrics.classification import MulticlassJaccardIndex >>> target = torch.tensor([2, 1, 0, 0]) >>> preds = torch.tensor([ ... [0.16, 0.26, 0.58], ... [0.22, 0.61, 0.17], ... [0.71, 0.09, 0.20], ... [0.05, 0.82, 0.13], ... ]) >>> metric = MulticlassJaccardIndex(num_classes=3) >>> metric(preds, target) tensor(0.6667)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
MultilabelJaccardIndex¶
- class torchmetrics.classification.MultilabelJaccardIndex(num_labels, threshold=0.5, average='macro', ignore_index=None, validate_args=True, **kwargs)[source]
Calculates the Jaccard index for multilabel tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds(int or float tensor):(N, C, ...). If preds is a floating point tensor with values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element. Addtionally, we convert to int tensor with thresholding using the value inthreshold.target(int tensor):(N, C, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
num_classes¶ – Integer specifing the number of labels
threshold¶ (
float) – Threshold for transforming probability to binary (0,1) predictionsignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationaverage¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied over labels. Should be one of the following:
micro: Sum statistics over all labelsmacro: Calculate statistics for each label and average themweighted: Calculates statistics for each label and computes weighted average using their support"none"orNone: Calculates statistic for each label and applies no reduction
validate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
- Example (preds is int tensor):
>>> from torchmetrics.classification import MultilabelJaccardIndex >>> target = torch.tensor([[0, 1, 0], [1, 0, 1]]) >>> preds = torch.tensor([[0, 0, 1], [1, 0, 1]]) >>> metric = MultilabelJaccardIndex(num_labels=3) >>> metric(preds, target) tensor(0.5000)
- Example (preds is float tensor):
>>> from torchmetrics.classification import MultilabelJaccardIndex >>> target = torch.tensor([[0, 1, 0], [1, 0, 1]]) >>> preds = torch.tensor([[0.11, 0.22, 0.84], [0.73, 0.33, 0.92]]) >>> metric = MultilabelJaccardIndex(num_labels=3) >>> metric(preds, target) tensor(0.5000)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Functional Interface¶
jaccard_index¶
- torchmetrics.functional.jaccard_index(preds, target, num_classes, average='macro', ignore_index=None, absent_score=0.0, threshold=0.5, task=None, num_labels=None, validate_args=True)[source]
Note
From v0.10 an ‘binary_*’, ‘multiclass_*’, `’multilabel_*’ version now exist of each classification metric. Moving forward we recommend using these versions. This base metric will still work as it did prior to v0.10 until v0.11. From v0.11 the task argument introduced in this metric will be required and the general order of arguments may change, such that this metric will just function as an single entrypoint to calling the three specialized versions.
Computes Jaccard index
Where:
and are both tensors of the same size,
containing integer class values. They may be subject to conversion from
input data (see description below).Note that it is different from box IoU.
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument to convert into integer labels. This is the case for binary and multi-label probabilities.If pred has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
preds¶ (
Tensor) – tensor containing predictions from model (probabilities, or labels) with shape[N, d1, d2, ...]target¶ (
Tensor) – tensor containing ground truth labels with shape[N, d1, d2, ...]average¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied. Should be one of the following:
'macro'[default]: Calculate the metric for each class separately, and average the metrics across classes (with equal weights for each class).'micro': Calculate the metric globally, across all samples and classes.'weighted': Calculate the metric for each class separately, and average the metrics across classes, weighting each class by its support (tp + fn).'none'orNone: Calculate the metric for each class separately, and return the metric for every class. Note that if a given class doesn’t occur in the preds or target, the value for the class will benan.
ignore_index¶ (
Optional[int]) – optional int specifying a target class to ignore. If given, this class index does not contribute to the returned score, regardless of reduction method. Has no effect if given an int that is not in the range[0, num_classes-1], where num_classes is either given or derived from pred and target. By default, no index is ignored, and all classes are used.absent_score¶ (
float) – score to use for an individual class, if no instances of the class index were present inpredsAND no instances of the class index were present intarget. For example, if we have 3 classes, [0, 0] forpreds, and [0, 2] fortarget, then class 1 would be assigned the absent_score.threshold¶ (
float) – Threshold value for binary or multi-label probabilities.
- Return type
- Returns
The shape of the returned tensor depends on the
averageparameterIf
average in ['micro', 'macro', 'weighted'], a one-element tensor will be returnedIf
average in ['none', None], the shape will be(C,), whereCstands for the number of classes
Example
>>> from torchmetrics.functional import jaccard_index >>> target = torch.randint(0, 2, (10, 25, 25)) >>> pred = torch.tensor(target) >>> pred[2:5, 7:13, 9:15] = 1 - pred[2:5, 7:13, 9:15] >>> jaccard_index(pred, target, num_classes=2) tensor(0.9660)
binary_jaccard_index¶
- torchmetrics.functional.classification.binary_jaccard_index(preds, target, threshold=0.5, ignore_index=None, validate_args=True)[source]
Calculates the Jaccard index for binary tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds(int or float tensor):(N, ...). If preds is a floating point tensor with values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element. Addtionally, we convert to int tensor with thresholding using the value inthreshold.target(int tensor):(N, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
threshold¶ (
float) – Threshold for transforming probability to binary (0,1) predictionsignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationnormalize¶ –
Normalization mode for confusion matrix. Choose from:
Noneor'none': no normalization (default)'true': normalization over the targets (most commonly used)'pred': normalization over the predictions'all': normalization over the whole matrix
validate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ – Additional keyword arguments, see Advanced metric settings for more info.
- Example (preds is int tensor):
>>> from torchmetrics.functional.classification import binary_jaccard_index >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0, 1, 0, 0]) >>> binary_jaccard_index(preds, target) tensor(0.5000)
- Example (preds is float tensor):
>>> from torchmetrics.functional.classification import binary_jaccard_index >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0.35, 0.85, 0.48, 0.01]) >>> binary_jaccard_index(preds, target) tensor(0.5000)
- Return type
multiclass_jaccard_index¶
- torchmetrics.functional.classification.multiclass_jaccard_index(preds, target, num_classes, average='macro', ignore_index=None, validate_args=True)[source]
Calculates the Jaccard index for multiclass tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds:(N, ...)(int tensor) or(N, C, ..)(float tensor). If preds is a floating point we applytorch.argmaxalong theCdimension to automatically convert probabilities/logits into an int tensor.target(int tensor):(N, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
num_classes¶ (
int) – Integer specifing the number of classesaverage¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied over labels. Should be one of the following:
micro: Sum statistics over all labelsmacro: Calculate statistics for each label and average themweighted: Calculates statistics for each label and computes weighted average using their support"none"orNone: Calculates statistic for each label and applies no reduction
ignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationvalidate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ – Additional keyword arguments, see Advanced metric settings for more info.
- Example (pred is integer tensor):
>>> from torchmetrics.functional.classification import multiclass_jaccard_index >>> target = torch.tensor([2, 1, 0, 0]) >>> preds = torch.tensor([2, 1, 0, 1]) >>> multiclass_jaccard_index(preds, target, num_classes=3) tensor(0.6667)
- Example (pred is float tensor):
>>> from torchmetrics.functional.classification import multiclass_jaccard_index >>> target = torch.tensor([2, 1, 0, 0]) >>> preds = torch.tensor([ ... [0.16, 0.26, 0.58], ... [0.22, 0.61, 0.17], ... [0.71, 0.09, 0.20], ... [0.05, 0.82, 0.13], ... ]) >>> multiclass_jaccard_index(preds, target, num_classes=3) tensor(0.6667)
- Return type
multilabel_jaccard_index¶
- torchmetrics.functional.classification.multilabel_jaccard_index(preds, target, num_labels, threshold=0.5, average='macro', ignore_index=None, validate_args=True)[source]
Calculates the Jaccard index for multilabel tasks. The Jaccard index (also known as the intersetion over union or jaccard similarity coefficient) is an statistic that can be used to determine the similarity and diversity of a sample set. It is defined as the size of the intersection divided by the union of the sample sets:
Accepts the following input tensors:
preds(int or float tensor):(N, C, ...). If preds is a floating point tensor with values outside [0,1] range we consider the input to be logits and will auto apply sigmoid per element. Addtionally, we convert to int tensor with thresholding using the value inthreshold.target(int tensor):(N, C, ...)
Additional dimension
...will be flattened into the batch dimension.- Parameters
num_classes¶ – Integer specifing the number of labels
threshold¶ (
float) – Threshold for transforming probability to binary (0,1) predictionsaverage¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied over labels. Should be one of the following:
micro: Sum statistics over all labelsmacro: Calculate statistics for each label and average themweighted: Calculates statistics for each label and computes weighted average using their support"none"orNone: Calculates statistic for each label and applies no reduction
ignore_index¶ (
Optional[int]) – Specifies a target value that is ignored and does not contribute to the metric calculationvalidate_args¶ (
bool) – bool indicating if input arguments and tensors should be validated for correctness. Set toFalsefor faster computations.kwargs¶ – Additional keyword arguments, see Advanced metric settings for more info.
- Example (preds is int tensor):
>>> from torchmetrics.functional.classification import multilabel_jaccard_index >>> target = torch.tensor([[0, 1, 0], [1, 0, 1]]) >>> preds = torch.tensor([[0, 0, 1], [1, 0, 1]]) >>> multilabel_jaccard_index(preds, target, num_labels=3) tensor(0.5000)
- Example (preds is float tensor):
>>> from torchmetrics.functional.classification import multilabel_jaccard_index >>> target = torch.tensor([[0, 1, 0], [1, 0, 1]]) >>> preds = torch.tensor([[0.11, 0.22, 0.84], [0.73, 0.33, 0.92]]) >>> multilabel_jaccard_index(preds, target, num_labels=3) tensor(0.5000)
- Return type
