Word Info. Preserved¶
Module Interface¶
- class torchmetrics.WordInfoPreserved(**kwargs)[source]
Word Information Preserved (WIP) is a metric of the performance of an automatic speech recognition system. This value indicates the percentage of words that were correctly predicted between a set of ground- truth sentences and a set of hypothesis sentences. The higher the value, the better the performance of the ASR system with a WordInfoPreserved of 1 being a perfect score. Word Information Preserved rate can then be computed as:
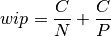
where:
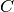 is the number of correct words,
is the number of correct words,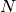 is the number of words in the reference
is the number of words in the reference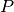 is the number of words in the prediction
is the number of words in the prediction
As input to
forwardandupdatethe metric accepts the following input:preds(List): Transcription(s) to score as a string or list of stringstarget(List): Reference(s) for each speech input as a string or list of strings
As output of
forwardandcomputethe metric returns the following output:wip(Tensor): A tensor with the Word Information Preserved score
- Parameters
kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
Examples
>>> from torchmetrics import WordInfoPreserved >>> preds = ["this is the prediction", "there is an other sample"] >>> target = ["this is the reference", "there is another one"] >>> wip = WordInfoPreserved() >>> wip(preds, target) tensor(0.3472)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Functional Interface¶
- torchmetrics.functional.word_information_preserved(preds, target)[source]
Word Information Preserved rate is a metric of the performance of an automatic speech recognition system. This value indicates the percentage of characters that were incorrectly predicted. The lower the value, the better the performance of the ASR system with a Word Information preserved rate of 0 being a perfect score.
- Parameters
- Return type
- Returns
Word Information preserved rate
Examples
>>> from torchmetrics.functional import word_information_preserved >>> preds = ["this is the prediction", "there is an other sample"] >>> target = ["this is the reference", "there is another one"] >>> word_information_preserved(preds, target) tensor(0.3472)
