Dice¶
Module Interface¶
- class torchmetrics.Dice(zero_division=0, num_classes=None, threshold=0.5, average='micro', mdmc_average='global', ignore_index=None, top_k=None, multiclass=None, **kwargs)[source]
Computes Dice:
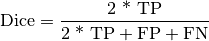
Where
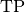 and
and 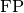 represent the number of true positives and
false positives respecitively.
represent the number of true positives and
false positives respecitively.It is recommend set ignore_index to index of background class.
The reduction method (how the precision scores are aggregated) is controlled by the
averageparameter, and additionally by themdmc_averageparameter in the multi-dimensional multi-class case. Accepts all inputs listed in Input types.- Parameters
num_classes¶ (
Optional[int]) – Number of classes. Necessary for'macro','weighted'andNoneaverage methods.threshold¶ (
float) – Threshold for transforming probability or logit predictions to binary (0,1) predictions, in the case of binary or multi-label inputs. Default value of 0.5 corresponds to input being probabilities.zero_division¶ (
int) – The value to use for the score if denominator equals zero.average¶ (
Optional[Literal[‘micro’, ‘macro’, ‘weighted’, ‘none’]]) –Defines the reduction that is applied. Should be one of the following:
'micro'[default]: Calculate the metric globally, across all samples and classes.'macro': Calculate the metric for each class separately, and average the metrics across classes (with equal weights for each class).'weighted': Calculate the metric for each class separately, and average the metrics across classes, weighting each class by its support (tp + fn).'none'orNone: Calculate the metric for each class separately, and return the metric for every class.'samples': Calculate the metric for each sample, and average the metrics across samples (with equal weights for each sample).
Note
What is considered a sample in the multi-dimensional multi-class case depends on the value of
mdmc_average.mdmc_average¶ (
Optional[str]) –Defines how averaging is done for multi-dimensional multi-class inputs (on top of the
averageparameter). Should be one of the following:None[default]: Should be left unchanged if your data is not multi-dimensional multi-class.'samplewise': In this case, the statistics are computed separately for each sample on theNaxis, and then averaged over samples. The computation for each sample is done by treating the flattened extra axes...(see Input types) as theNdimension within the sample, and computing the metric for the sample based on that.'global': In this case theNand...dimensions of the inputs (see Input types) are flattened into a newN_Xsample axis, i.e. the inputs are treated as if they were(N_X, C). From here on theaverageparameter applies as usual.
ignore_index¶ (
Optional[int]) – Integer specifying a target class to ignore. If given, this class index does not contribute to the returned score, regardless of reduction method. If an index is ignored, andaverage=Noneor'none', the score for the ignored class will be returned asnan.top_k¶ (
Optional[int]) – Number of the highest probability or logit score predictions considered finding the correct label, relevant only for (multi-dimensional) multi-class inputs. The default value (None) will be interpreted as 1 for these inputs. Should be left at default (None) for all other types of inputs.multiclass¶ (
Optional[bool]) – Used only in certain special cases, where you want to treat inputs as a different type than what they appear to be. See the parameter’s documentation section for a more detailed explanation and examples.kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
- Raises
ValueError – If
averageis none of"micro","macro","weighted","samples","none",None.ValueError – If
mdmc_averageis not one ofNone,"samplewise","global".ValueError – If
averageis set butnum_classesis not provided.ValueError – If
num_classesis set andignore_indexis not in the range[0, num_classes).
Example
>>> import torch >>> from torchmetrics import Dice >>> preds = torch.tensor([2, 0, 2, 1]) >>> target = torch.tensor([1, 1, 2, 0]) >>> dice = Dice(average='micro') >>> dice(preds, target) tensor(0.2500)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- compute()[source]
Computes the dice score based on inputs passed in to
updatepreviously.- Returns
If
average in ['micro', 'macro', 'weighted', 'samples'], a one-element tensor will be returnedIf
average in ['none', None], the shape will be(C,), whereCstands for the number of classes
- Return type
The shape of the returned tensor depends on the
averageparameter
Functional Interface¶
- torchmetrics.functional.dice(preds, target, zero_division=0, average='micro', mdmc_average='global', threshold=0.5, top_k=None, num_classes=None, multiclass=None, ignore_index=None)[source]
Computes Dice:
Where
and 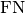 represent the number of true positives and
false negatives respecitively.
represent the number of true positives and
false negatives respecitively.It is recommend set ignore_index to index of background class.
The reduction method (how the recall scores are aggregated) is controlled by the
averageparameter, and additionally by themdmc_averageparameter in the multi-dimensional multi-class case. Accepts all inputs listed in Input types.- Parameters
preds¶ (
Tensor) – Predictions from model (probabilities, logits or labels)zero_division¶ (
int) – The value to use for the score if denominator equals zeroDefines the reduction that is applied. Should be one of the following:
'micro'[default]: Calculate the metric globally, across all samples and classes.'macro': Calculate the metric for each class separately, and average the metrics across classes (with equal weights for each class).'weighted': Calculate the metric for each class separately, and average the metrics across classes, weighting each class by its support (tp + fn).'none'orNone: Calculate the metric for each class separately, and return the metric for every class.'samples': Calculate the metric for each sample, and average the metrics across samples (with equal weights for each sample).
Note
What is considered a sample in the multi-dimensional multi-class case depends on the value of
mdmc_average.Note
If
'none'and a given class doesn’t occur in thepredsortarget, the value for the class will benan.mdmc_average¶ (
Optional[str]) –Defines how averaging is done for multi-dimensional multi-class inputs (on top of the
averageparameter). Should be one of the following:None[default]: Should be left unchanged if your data is not multi-dimensional multi-class.'samplewise': In this case, the statistics are computed separately for each sample on theNaxis, and then averaged over samples. The computation for each sample is done by treating the flattened extra axes...(see Input types) as theNdimension within the sample, and computing the metric for the sample based on that.'global': In this case theNand...dimensions of the inputs (see Input types) are flattened into a newN_Xsample axis, i.e. the inputs are treated as if they were(N_X, C). From here on theaverageparameter applies as usual.
ignore_index¶ (
Optional[int]) – Integer specifying a target class to ignore. If given, this class index does not contribute to the returned score, regardless of reduction method. If an index is ignored, andaverage=Noneor'none', the score for the ignored class will be returned asnan.num_classes¶ (
Optional[int]) – Number of classes. Necessary for'macro','weighted'andNoneaverage methods.threshold¶ (
float) – Threshold for transforming probability or logit predictions to binary (0,1) predictions, in the case of binary or multi-label inputs. Default value of 0.5 corresponds to input being probabilities.Number of the highest probability or logit score predictions considered finding the correct label, relevant only for (multi-dimensional) multi-class inputs. The default value (
None) will be interpreted as 1 for these inputs.Should be left at default (
None) for all other types of inputs.multiclass¶ (
Optional[bool]) – Used only in certain special cases, where you want to treat inputs as a different type than what they appear to be. See the parameter’s documentation section for a more detailed explanation and examples.
- Return type
- Returns
The shape of the returned tensor depends on the
averageparameterIf
average in ['micro', 'macro', 'weighted', 'samples'], a one-element tensor will be returnedIf
average in ['none', None], the shape will be(C,), whereCstands for the number of classes
- Raises
ValueError – If
averageis not one of"micro","macro","weighted","samples","none"orNoneValueError – If
mdmc_averageis not one ofNone,"samplewise","global".ValueError – If
averageis set butnum_classesis not provided.ValueError – If
num_classesis set andignore_indexis not in the range[0, num_classes).
Example
>>> from torchmetrics.functional import dice >>> preds = torch.tensor([2, 0, 2, 1]) >>> target = torch.tensor([1, 1, 2, 0]) >>> dice(preds, target, average='micro') tensor(0.2500)
Dice Score¶
Functional Interface (was deprecated in v0.9)¶
- torchmetrics.functional.dice_score(preds, target, bg=False, nan_score=0.0, no_fg_score=0.0, reduction='elementwise_mean')[source]
Compute dice score from prediction scores.
Supports only “macro” approach, which mean calculate the metric for each class separately, and average the metrics across classes (with equal weights for each class).
Deprecated since version v0.9: The dice_score function was deprecated in v0.9 and will be removed in v0.10. Use dice function instead.
- Parameters
bg¶ (
bool) – whether to also compute dice for the backgroundnan_score¶ (
float) – score to return, if a NaN occurs during computation(default,
0.0) score to return, if no foreground pixel was found in targetDeprecated since version v0.9: All different from default options will be changed to default.
reduction¶ (
Literal[‘elementwise_mean’, ‘sum’, ‘none’, None]) –(default,
'elementwise_mean') a method to reduce metric score over labels.Deprecated since version v0.9: All different from default options will be changed to default.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none'orNone: no reduction will be applied
- Return type
- Returns
Tensor containing dice score
Example
>>> from torchmetrics.functional import dice_score >>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> dice_score(pred, target) tensor(0.3333)
