Signal-to-Noise Ratio (SNR)¶
Module Interface¶
- class torchmetrics.SignalNoiseRatio(zero_mean=False, compute_on_step=None, **kwargs)[source]
Signal-to-noise ratio (SNR):
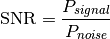
where
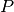 denotes the power of each signal. The SNR metric compares the level
of the desired signal to the level of background noise. Therefore, a high value of
SNR means that the audio is clear.
denotes the power of each signal. The SNR metric compares the level
of the desired signal to the level of background noise. Therefore, a high value of
SNR means that the audio is clear.Forward accepts
preds:shape [..., time]target:shape [..., time]
- Parameters
- Raises
TypeError – if target and preds have a different shape
- Returns
average snr value
Example
>>> import torch >>> from torchmetrics import SignalNoiseRatio >>> target = torch.tensor([3.0, -0.5, 2.0, 7.0]) >>> preds = torch.tensor([2.5, 0.0, 2.0, 8.0]) >>> snr = SignalNoiseRatio() >>> snr(preds, target) tensor(16.1805)
References
[1] Le Roux, Jonathan, et al. “SDR half-baked or well done.” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2019.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Functional Interface¶
- torchmetrics.functional.signal_noise_ratio(preds, target, zero_mean=False)[source]
Signal-to-noise ratio (SNR):
where
denotes the power of each signal. The SNR metric compares the level
of the desired signal to the level of background noise. Therefore, a high value of
SNR means that the audio is clear.- Parameters
- Return type
- Returns
snr value of shape […]
Example
>>> from torchmetrics.functional.audio import signal_noise_ratio >>> target = torch.tensor([3.0, -0.5, 2.0, 7.0]) >>> preds = torch.tensor([2.5, 0.0, 2.0, 8.0]) >>> signal_noise_ratio(preds, target) tensor(16.1805)
References
[1] Le Roux, Jonathan, et al. “SDR half-baked or well done.” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2019.
