KL Divergence¶
Module Interface¶
- class torchmetrics.KLDivergence(log_prob=False, reduction='mean', **kwargs)[source]
Computes the KL divergence:
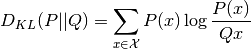
Where
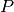 and
and 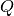 are probability distributions where usually represents a distribution
over data and is often a prior or approximation of . It should be noted that the KL divergence
is a non-symetrical metric i.e.
are probability distributions where usually represents a distribution
over data and is often a prior or approximation of . It should be noted that the KL divergence
is a non-symetrical metric i.e. 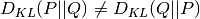 .
.As input to
forwardandupdatethe metric accepts the following input:p(Tensor): a data distribution with shape(N, d)q(Tensor): prior or approximate distribution with shape(N, d)
As output of
forwardandcomputethe metric returns the following output:kl_divergence(Tensor): A tensor with the KL divergence
- Parameters
log_prob¶ (
bool) – bool indicating if input is log-probabilities or probabilities. If given as probabilities, will normalize to make sure the distributes sum to 1.reduction¶ (
Literal[‘mean’, ‘sum’, ‘none’, None]) –Determines how to reduce over the
N/batch dimension:'mean'[default]: Averages score across samples'sum': Sum score across samples'none'orNone: Returns score per sample
kwargs¶ (
Any) – Additional keyword arguments, see Advanced metric settings for more info.
- Raises
TypeError – If
log_probis not anbool.ValueError – If
reductionis not one of'mean','sum','none'orNone.
Note
Half precision is only support on GPU for this metric
Example
>>> import torch >>> from torchmetrics.functional import kl_divergence >>> p = torch.tensor([[0.36, 0.48, 0.16]]) >>> q = torch.tensor([[1/3, 1/3, 1/3]]) >>> kl_divergence(p, q) tensor(0.0853)
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Functional Interface¶
- torchmetrics.functional.kl_divergence(p, q, log_prob=False, reduction='mean')[source]
Computes KL divergence
Where
and are probability distributions where usually represents a distribution
over data and is often a prior or approximation of . It should be noted that the KL divergence
is a non-symetrical metric i.e. .- Parameters
q¶ (
Tensor) – prior or approximate distribution with shape[N, d]log_prob¶ (
bool) – bool indicating if input is log-probabilities or probabilities. If given as probabilities, will normalize to make sure the distributes sum to 1reduction¶ (
Literal[‘mean’, ‘sum’, ‘none’, None]) –Determines how to reduce over the
N/batch dimension:'mean'[default]: Averages score across samples'sum': Sum score across samples'none'orNone: Returns score per sample
Example
>>> import torch >>> p = torch.tensor([[0.36, 0.48, 0.16]]) >>> q = torch.tensor([[1/3, 1/3, 1/3]]) >>> kl_divergence(p, q) tensor(0.0853)
- Return type
